蚂蚁集团旗下的AI安全实验室,近期针对开源智能体框架OpenClaw开展了一次专项安全审计工作。在持续三天的检测过程中,该团队累计提交了33份漏洞报告。在OpenClaw最新推出的2026.3.28版本里,已核实并修复了其中的8个漏洞,具体包含1个严重级漏洞、4个高危漏洞和3个中危漏洞。
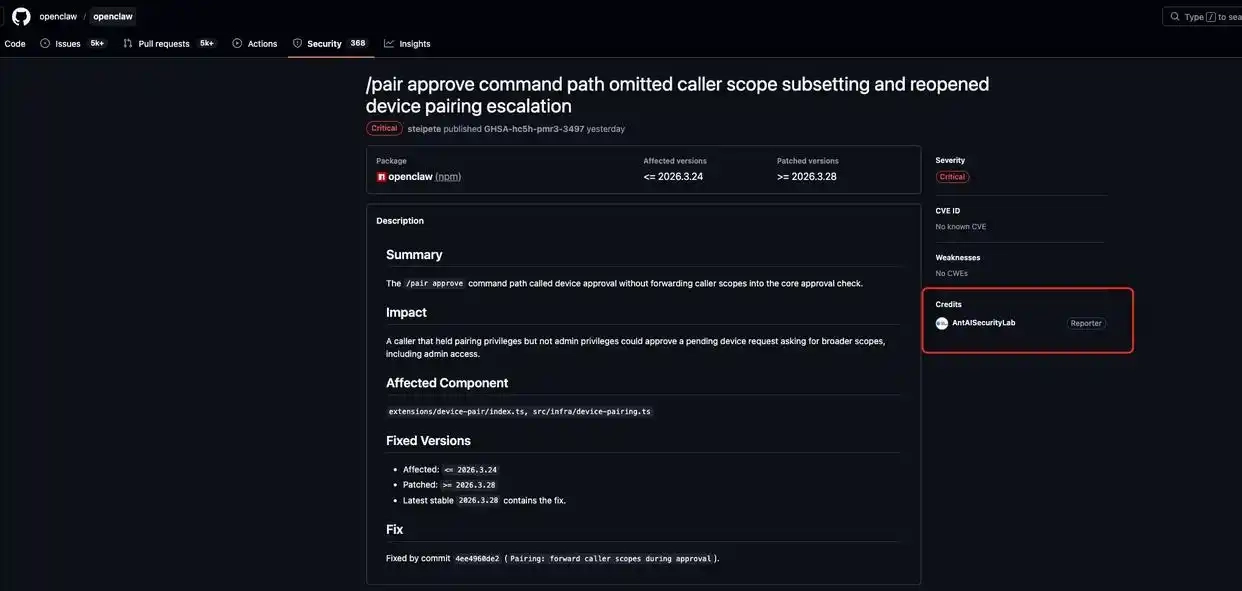
(图片来源:GitHub)
真正值得担忧的并非OpenClaw本身作为传统开发工具的属性,而是它所代表的当下最受关注的AI产品形态——Agent。过去一年,随着大模型技术日趋成熟,行业的讨论焦点也在悄然转变:从最初围绕“模型能力的比拼”,慢慢过渡到“如何让AI应用真正落地”。而Agent正是这一转变过程中最核心的环节,它的价值远不止于内容生成,更在于能够自主调用各类工具、执行具体任务,甚至直接介入系统层面的操作。
传统大模型的应用风险,主要聚焦于内容维度,像生成错误信息、不当回应或是输出不受控的内容,核心问题其实还是信息输出的偏差。但Agent的运行逻辑有所不同,其行动执行能力才是关键所在,比如能够调用系统资源、访问本地文件、执行指令流程。这意味着,Openclaw所存在的漏洞,确实潜藏着各类难以预估的安全隐患。
(图片来源:Openclaw)
目前公开渠道尚未公布此次漏洞的具体技术细节,不过从其“严重”“高危”的评级判断,能够明确的是,这些问题大概率涉及权限管控、执行流程或调用机制等核心环节。也就是说,一旦被不法分子利用,影响将不只是停留在信息层面,还可能直接威胁到系统本身,例如导致个人信息外泄、财产安全受到侵害等情况。
从行业视角来看,Openclaw遇到的问题实际上是所有Agent都要共同应对的挑战。过去一年,行业几乎将全部精力都放在了提升Agent的“聪明度”上——比如实现更复杂的任务步骤拆解、调用更多工具与Skill来解决问题、增强自动任务执行能力等,但权限隔离、风险控制、执行边界这些关键议题,却似乎很少被提及。
不过,此次曝出大量漏洞的蚂蚁集团旗下AI安全实验室,之所以能最早发现问题,是因为该团队早在大模型全面爆发之前,就已围绕“可信AI”开展研究,涵盖对抗攻击、数据安全等方向,之后还发布过《终端智能体安全2025》白皮书,剖析AI的安全风险等内容。
 蓝色星原旅谣叶冠驼技能介绍
蓝色星原旅谣叶冠驼技能介绍
 接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
 GamePass新层级被曝光仅可游玩Xbox第一方游戏
GamePass新层级被曝光仅可游玩Xbox第一方游戏
 愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
 最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
 无双全明星中低调行动的男性角色奖杯解锁条件汇总
无双全明星中低调行动的男性角色奖杯解锁条件汇总
 小米手机的发展前景不容乐观,库存积压问题严重
小米手机的发展前景不容乐观,库存积压问题严重
 独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台
独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台