3月27日消息,美团于今日推出原生多模态大模型LongCat-Next。该模型能够把图像、语音和文本统一转化为同源的离散Token,让模型的学习方式从对连续空间映射的学习,转变为对离散ID之间关系结构的学习。同时,它借助纯粹的下一个Token预测(Next Token Prediction, NTP)范式,以统一的方法对各类物理信号进行建模。

美团还宣布将其研究思路的核心——LongCat-Next模型及其离散分词器全部开源,期待更多开发者能以此为基础,打造出真正可以感知、理解并作用于现实世界的人工智能。
美团打造了DiNA(Discrete Native Autoregressive)离散原生自回归架构。该架构的核心在于把所有模态整合为离散Token,借助同一个自回归模型开展建模工作。DiNA消除了模态之间的壁垒,它依托简洁的下一Token预测(NTP)模式,将图像、声音与文字统一转换为同源的离散Token。
简单来说,美团将文字、图像和语音都转化为同一种形式——离散Token。不管是处理文字、图像还是声音,在AI看来都是一样的任务:预测下一个Token是什么。
这种统一化的设计思路,使得模型在训练阶段的稳定性得到提升,同时在部署环节也更为轻量化。美团选择 LongCat-Flash-Lite MoE(总参数达 68.5B,激活参数为 3B)作为基础模型,并在该框架之上进一步训练出了 LongCat-Next。
实验表明,DiNA 的 MoE 路由在训练中逐渐出现模态专精化,激活专家数量相比纯语言设置有所增加,模型正在用更大容量支撑能力扩展。
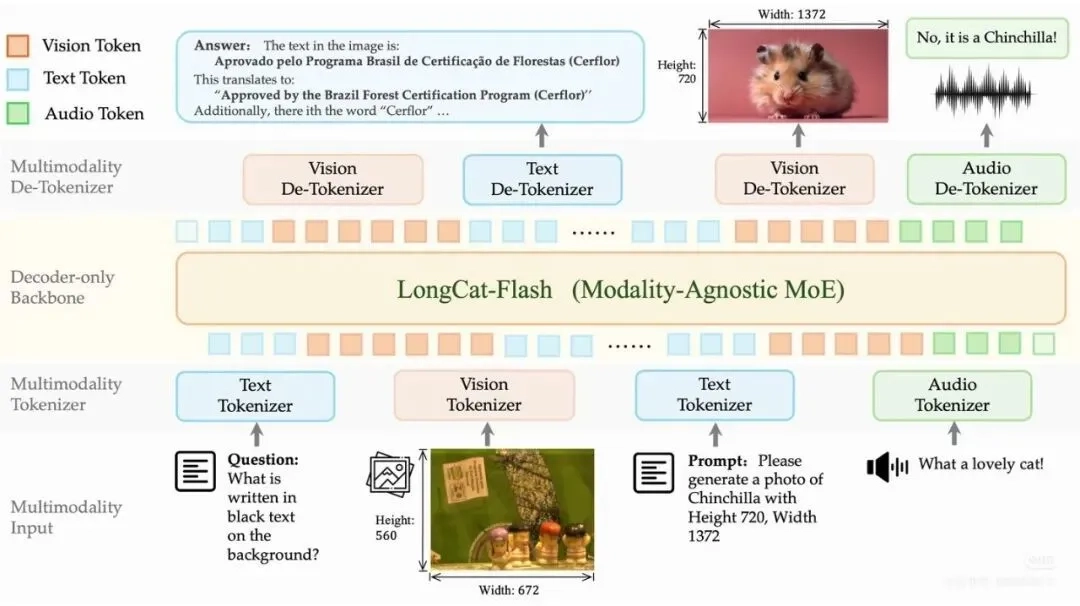
▲ LongCat-Next 架构概览,该架构基于 DiNA 范式设计
根据美团官方测试,LongCat-Next 在视觉理解、图像生成、音频、智能体等多个维度上,以一套离散原生框架展现出与多模专用模型相当甚至领先的性能。
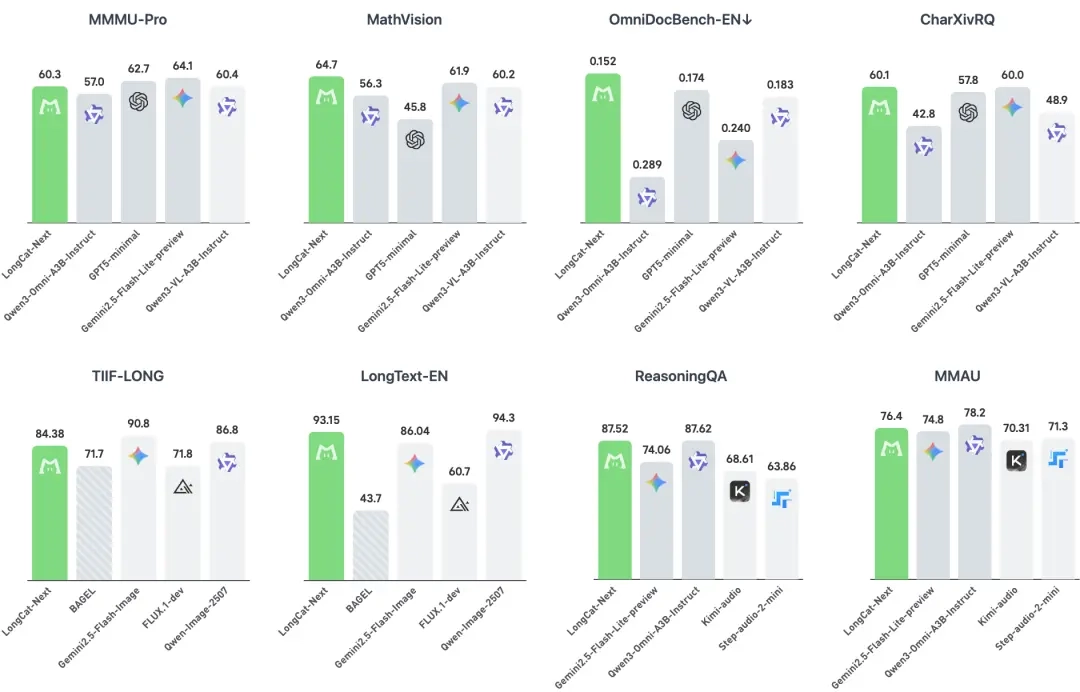
LongCat-Next 在 OmniDocBench(涵盖学术论文、财报、行政表格等场景)的表现数据为 0.152 / 0.226,这一成绩不仅优于 Qwen3-Omni,甚至超过了专注于视觉任务的模型 Qwen3-VL。
在消融实验的对比中,LongCat-Next统一模型的理解损失仅比纯理解模型高出0.006,而生成损失则比纯生成模型低0.02。在图像生成任务方面,LongCat-Next在LongText-Bench上取得了93.15的成绩(英文);在图像理解任务上,其在MathVista数据集上达到了83.1的领先水平。
在纯文本任务领域,LongCat-Next 在 MMLU-Pro(77.02)与 C-Eval(86.80)两项指标上均处于领先位置,这表明原生多模态训练并未对其语言核心能力造成削弱。在工具调用方面,τ²-Bench 零售场景测试中,LongCat-Next 以73.68的成绩显著领先于 Qwen3-Next-80B-A3B-Instruct(57.3);而在代码能力的 SWE-Bench 评测中,该模型也取得了43.0的成绩,超越了同类模型。
在音频领域,SeedTTS在TTS任务中的中文和英文WER分别低至1.90与1.89;在音频理解方面,MMAU(76.40)和TUT2017(43.09)均实现了先进水平。尤为关键的是,该模型支持低延迟的并行文本语音生成以及可定制的语音克隆功能,使得语音交互更为自然且更具个性化。
 接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
 蓝色星原旅谣叶冠驼技能介绍
蓝色星原旅谣叶冠驼技能介绍
 愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
 19岁少年团队实力超群,1.5万人携手打造太阳能汽车
19岁少年团队实力超群,1.5万人携手打造太阳能汽车
 无双全明星中低调行动的男性角色奖杯解锁条件汇总
无双全明星中低调行动的男性角色奖杯解锁条件汇总
 最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
 独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台
独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台
 星绘友晴天健康冰淇淋的制作步骤
星绘友晴天健康冰淇淋的制作步骤