谷歌正推出基于Gemini 3.1 Flash的全新文本转语音模型。据该公司介绍,这是其目前发布的声音输出最自然、表现力最强的模型。其中最主要的新特性是音频标签——通过简洁的文本指令,开发者可对生成语音的风格、节奏、语气及口音进行调控。该模型支持七十多种语言,还能处理多说话者的对话场景。
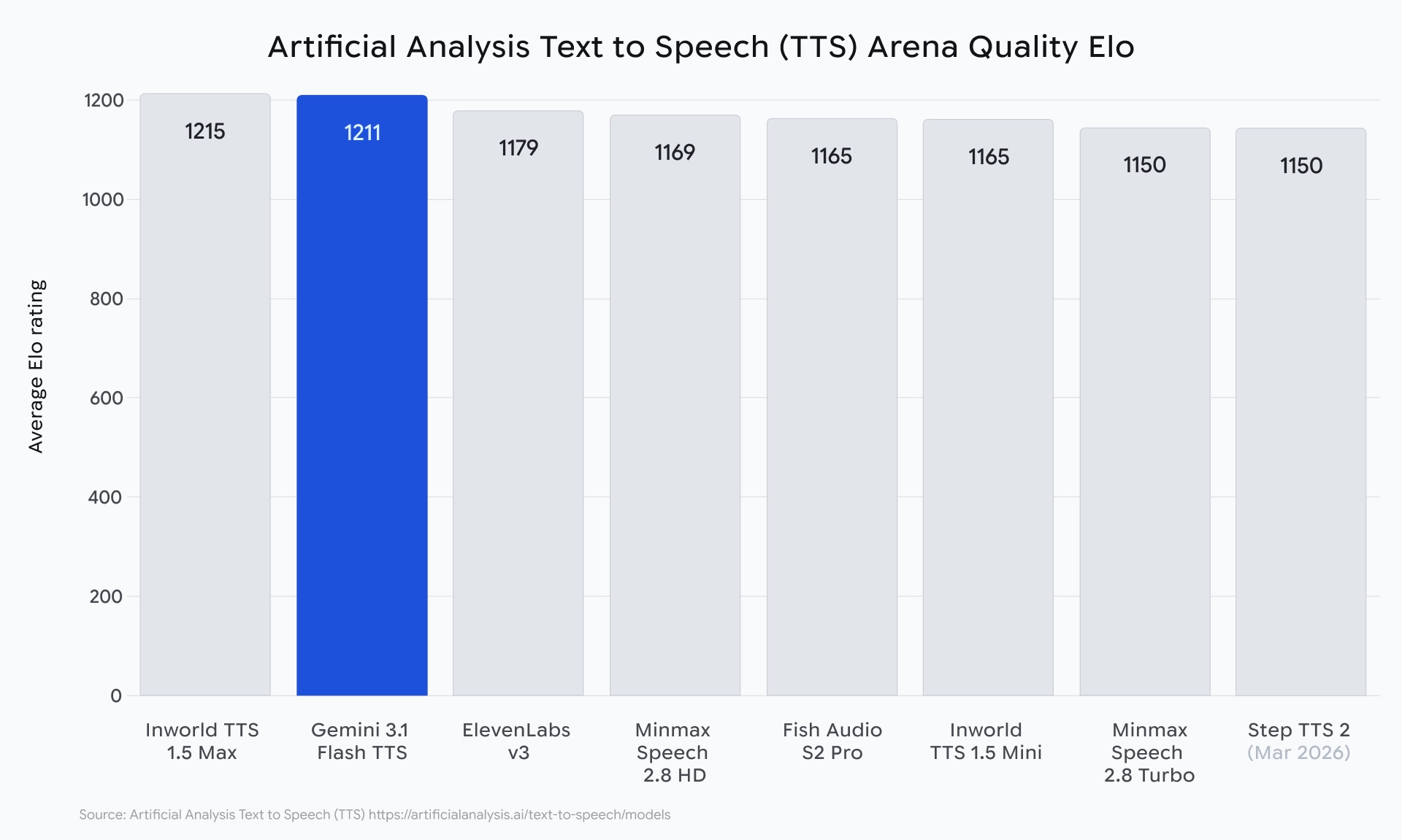
在人工分析的排名榜单中,这款模型的Elo评分达到1211分,凭借出色的性价比崭露头角。其整体质量不仅超越了Elevenlabs v3,还仅次于Inworld 1.5 Max。
Gemini 3.1 Flash TTS提供免费使用的套餐,不过谷歌会借助这些数据来优化自身产品。付费版本中,文本输入的费用是每百万代币1.00美元,音频输出则是每百万代币20.00美元。若使用批量模式,价格会降低一半,分别变为0.50美元和10美元。而在付费层级下,谷歌不会把这些数据用于产品改进。
Gemini 3.1 Flash TTS 目前可通过 Gemini API 进行预览,企业用户可借助 Vertex AI 使用,Workspace 用户则能通过 Google Vids 体验。此外,任何人都可以在谷歌的 AI Studio 中免费试用该功能。值得注意的是,所有生成的音频都会带有谷歌的 SynthID 水印标记,以此来标识 AI 生成的内容。
 蓝色星原旅谣叶冠驼技能介绍
蓝色星原旅谣叶冠驼技能介绍
 GamePass新层级被曝光仅可游玩Xbox第一方游戏
GamePass新层级被曝光仅可游玩Xbox第一方游戏
 接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
 愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
 最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
 小米手机的发展前景不容乐观,库存积压问题严重
小米手机的发展前景不容乐观,库存积压问题严重
 无双全明星中低调行动的男性角色奖杯解锁条件汇总
无双全明星中低调行动的男性角色奖杯解锁条件汇总
 独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台
独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台