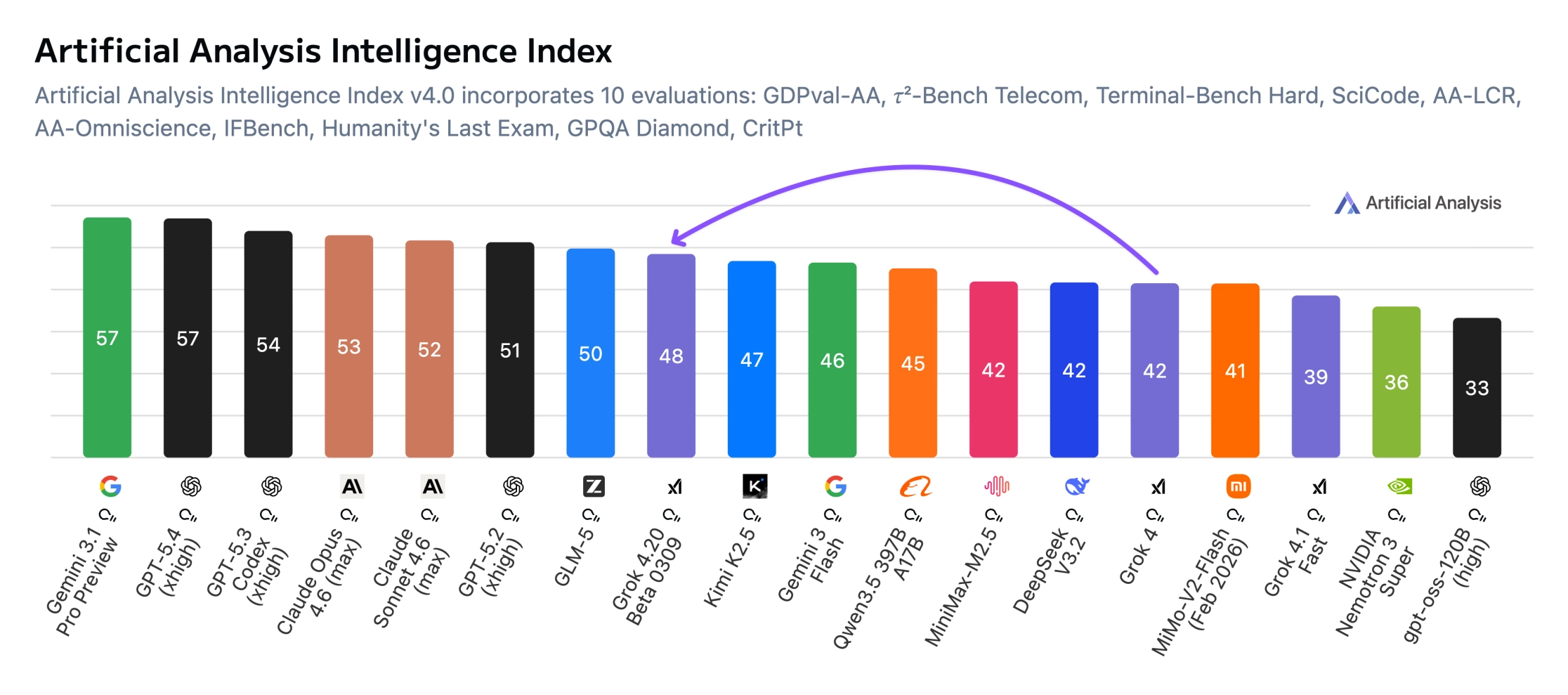
xAI的Grok 4.20在基准测试中未能赶上顶级AI模型的水平,不过其幻觉现象比其他测试过的模型都要少。依据Artificial Analysis的数据,开启推理功能后,Grok 4.20 Beta的智力指数为48分,这一分数远低于Gemini 3.1 Pro Preview和GPT-5.4的57分,但相比Grok 4还是提高了6分。
xAI推出了三种API版本:包含推理功能、不含推理功能以及多智能体模式。该模型拥有200万代币的上下文窗口,费用为每百万代币2美元或6美元;相比Grok 4价格更低,在西方同类模型中定价具备竞争力。
Grok 4.20最显著的特点在于事实的可靠性。在AA全知测试中,经人工分析,其非幻觉率高达78%,创下了新纪录。该测试衡量的是模型编造答案的频率,而非承认自身无知的情况,同时还结合了事实回忆能力的考察。Grok 4.20仅有五分之一的答错情况是因无法给出答案导致的。
 接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
 蓝色星原旅谣叶冠驼技能介绍
蓝色星原旅谣叶冠驼技能介绍
 愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
 GamePass新层级被曝光仅可游玩Xbox第一方游戏
GamePass新层级被曝光仅可游玩Xbox第一方游戏
 无双全明星中低调行动的男性角色奖杯解锁条件汇总
无双全明星中低调行动的男性角色奖杯解锁条件汇总
 最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
 独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台
独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台
 小米手机的发展前景不容乐观,库存积压问题严重
小米手机的发展前景不容乐观,库存积压问题严重