人工智能初创企业Inception Labs发布了首款基于扩散技术的推理AI模型,该模型兼具高效与经济的特点。
和传统语言模型不一样的是,Mercury 2 会同时对多个文本块进行细化处理,并非逐字逐句地加工文本。这家初创企业将此类比为编辑一次性对整个草稿进行修改,而非只关注单个字词。
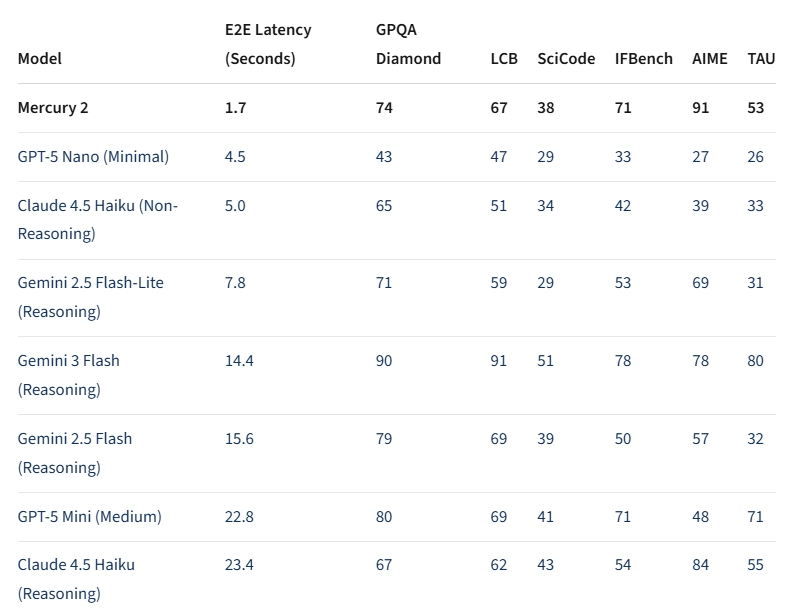
目前最突出的优势体现在速度与价格两方面。根据《盗梦空间》的相关报道,Mercury 2在Nvidia Blackwell GPU上的处理速度达到了每秒1009个令牌,端到端延迟仅1.7秒;相比之下,启用推理功能时,Gemini 3闪存的延迟为14.4秒,Claude Haiku 4.5则为23.4秒。该公司表示,其输出质量能够与当前领先的速度优化模型相媲美。
该服务的定价标准为:每百万输入代币收费0.25美元,每百万输出代币收费0.75美元。与Gemini 3 Flash(输入0.50美元/百万、输出3.00美元/百万)相比,输入价格低了一半,输出价格则低了四倍;而与Claude Haiku 4.5(输入1.00美元/百万、输出5.00美元/百万)相比,输入价格约为其四倍,输出价格则超过两倍半。
该模型具备128K上下文窗口支持,同时可实现工具调用与JSON格式输出。Inception主要面向那些有延迟敏感型应用需求的企业,例如语音助手、编程工具以及搜索系统等。
Mercury 2 目前已支持兼容 OpenAI 的 API 接口。企业可申请优先体验,该模型也能直接在聊天场景中进行测试。
人工智能行业正在寻找变形金刚之后的未来
去年11月,Inception从Microsoft、Nvidia、Snowflake等投资者处完成了5000万美元的融资。这家初创公司在2025年初对外展示了首个原型产品。而随着“水星2号”的发布,盗梦空间目前已推出搭载推理能力的量产机型。
Google Deepmind同样在开展基于扩散的语言模型研发工作。Gemini Diffusion在基准测试里的表现和当时的Gemini 2.0 Flash Lite模型不相上下。不过,自从2025年5月首次展示扩散实验后,谷歌至今还没有就这一扩散实验发布任何相关声明。
更宽泛地看,越来越多的初创企业正尝试探索替代主流变压器架构的途径。基于扩散的语言模型能否长期存续下去,目前还无法确定。
 蓝色星原旅谣叶冠驼技能介绍
蓝色星原旅谣叶冠驼技能介绍
 GamePass新层级被曝光仅可游玩Xbox第一方游戏
GamePass新层级被曝光仅可游玩Xbox第一方游戏
 接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
 愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
 最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
 小米手机的发展前景不容乐观,库存积压问题严重
小米手机的发展前景不容乐观,库存积压问题严重
 无双全明星中低调行动的男性角色奖杯解锁条件汇总
无双全明星中低调行动的男性角色奖杯解锁条件汇总
 独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台
独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台