OpenAI 推出了 GPT-5.3-Codex-Spark,该版本是为实时编程场景设计的 GPT-5.3 Codex 编码模型的轻量版本,它搭载于 Cerebras 芯片,每秒可处理超 1000 个令牌。
Codex-Spark 是 OpenAI 与 Cerebras 在今年一月宣布的合作项目中推出的首款产品,它运行在 Cerebras 专为快速推断打造的人工智能加速器——Wafer Scale Engine 3 之上。
研究预览目前已对ChatGPT Pro用户开放,用户可通过Codex应用、CLI以及VS Code扩展来使用。OpenAI称,计划在接下来的几周里拓宽访问范围。因为该模型是在专用硬件上运行的,所以公司指出会设置独立的速率限制,并且在需求高峰时段可能会对其进行调整。
Codex-Spark优先考虑速度而非自主性
OpenAI的大型前沿模型,像新推出的Codex 5.3,被设计成能自主运行数分钟乃至数小时,以完成复杂的编程任务。而Codex-Spark则采用了不同的思路:OpenAI指出,该模型是针对交互式工作优化的,延迟和智能一样关键。开发者能够实时中断并重新引导模型,还能立刻看到结果。
根据OpenAI的介绍,Codex-Spark在运营策略上特意保持了保守的风格。和大型模型相比,它默认情况下做出的修改幅度较小,并且只有当你给出明确指令时,才不会触发自动测试流程。这款模型配备了128k的上下文窗口,目前仅支持文本类内容的处理。
准确率下降,时间也有所下降
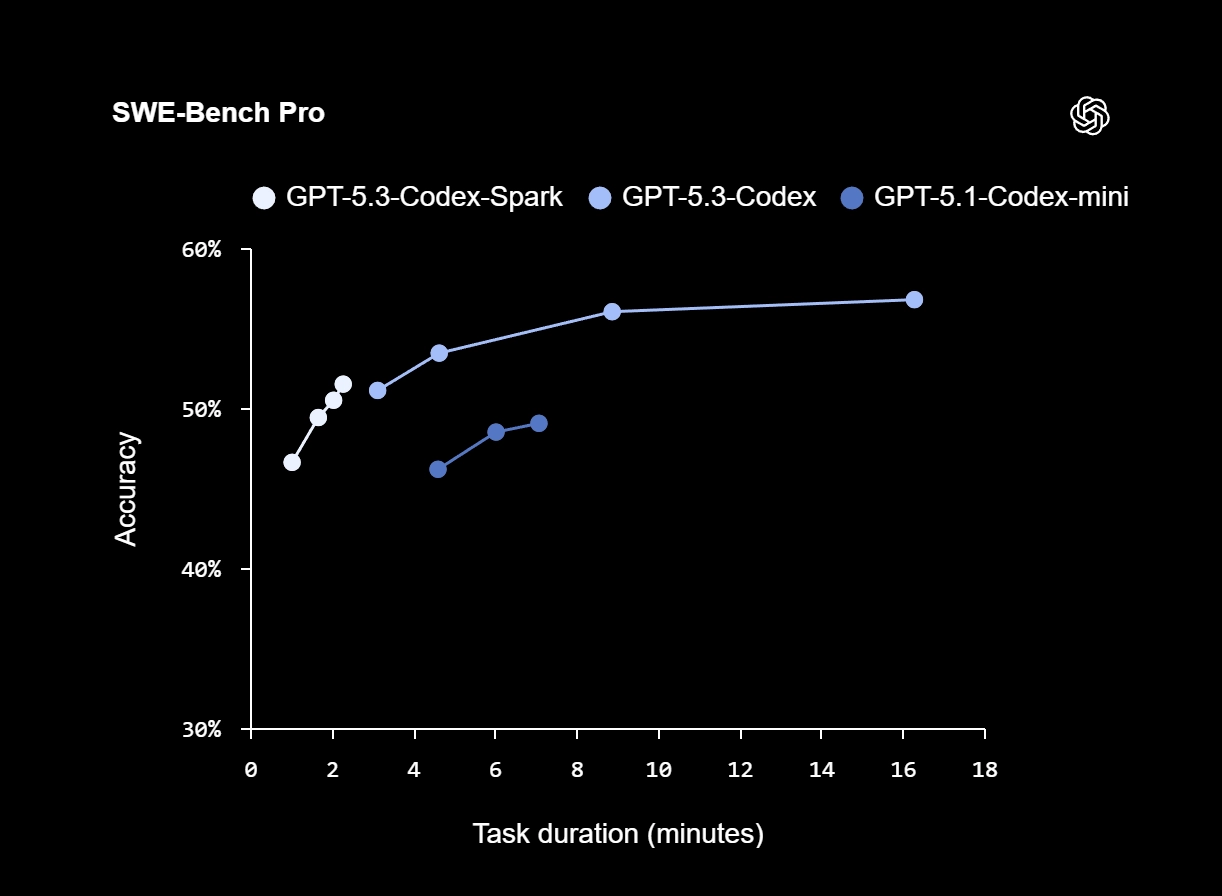
OpenAI称,Codex-Spark在评估基于代理的软件工程能力的SWE-Bench Pro和Terminal-Bench 2.0基准测试中表现出色,不过完成任务的耗时比GPT-5.3-Codex短得多。在SWE-Bench Pro测试中,Codex-Spark仅需约两到三分钟就能达到相近的精度,而GPT-5.3-Codex完成相同任务则大概需要15到17分钟。
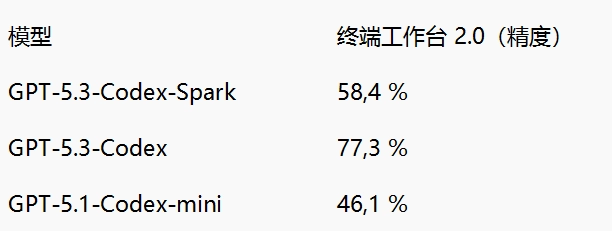
在终端工作台2.0里,Codex-Spark的准确率是58.4%。体积更大的GPT-5.3-Codex准确率达到77.3%,相比之下,较旧的GPT-5.1-Codex-mini准确率为46.1%。这两款较小的型号都是以速度为代价,换取了精准度的降低。
构建Codex-Spark这一任务,促使OpenAI在提升模型本身速度之外,还采取了多项关键优化措施。为达成延迟目标,公司对推理堆栈的核心部分进行了重写,优化了客户端与服务器间的响应流程,同时重新设计了会话启动机制,以加快首个令牌的显示速度。据OpenAI透露,这些优化带来的成果显著:往返开销降低了80%,单个代币开销减少30%,首个代币的生成时间缩短了一半。目前这些改进已默认应用于Codex-Spark,并将在近期推广至所有模型。
OpenAI 希望未来将实时模式和推理模式合并
OpenAI表示,Codex-Spark是计划中的“超快”模型家族中的首个型号。更多功能即将到来,包括更大的模型、更长的上下文窗口以及多模态输入支持。
从长远角度而言,公司正着力为Codex打造两种互补模式:其一用于拓展推理能力与自主执行任务,其二则服务于实时协作场景。OpenAI透露,计划逐步整合这两种模式,既让开发者能维持快速互动的循环,又可将较长耗时的任务交由后台子代理处理,或是把任务拆解后分配给多个并行运作的模型。
 蓝色星原旅谣叶冠驼技能介绍
蓝色星原旅谣叶冠驼技能介绍
 愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
 接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
 GamePass新层级被曝光仅可游玩Xbox第一方游戏
GamePass新层级被曝光仅可游玩Xbox第一方游戏
 最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
 独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台
独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台
 无双全明星中低调行动的男性角色奖杯解锁条件汇总
无双全明星中低调行动的男性角色奖杯解锁条件汇总
 小米手机的发展前景不容乐观,库存积压问题严重
小米手机的发展前景不容乐观,库存积压问题严重