3月28日消息,科技媒体The Decoder于昨日(3月27日)发布博文,称Meta旗下的基础人工智能研究团队(FAIR)已开源全新AI模型TRIBE v2,该模型能够精准预测人类大脑对图像、声音及文本的反应。
该模型最突出的优势在于,不必进行实际测量就能精准预测人类大脑对视觉、听觉与语言刺激的反应,这一特性有望突破传统神经科学研究周期漫长、成本高昂的限制。
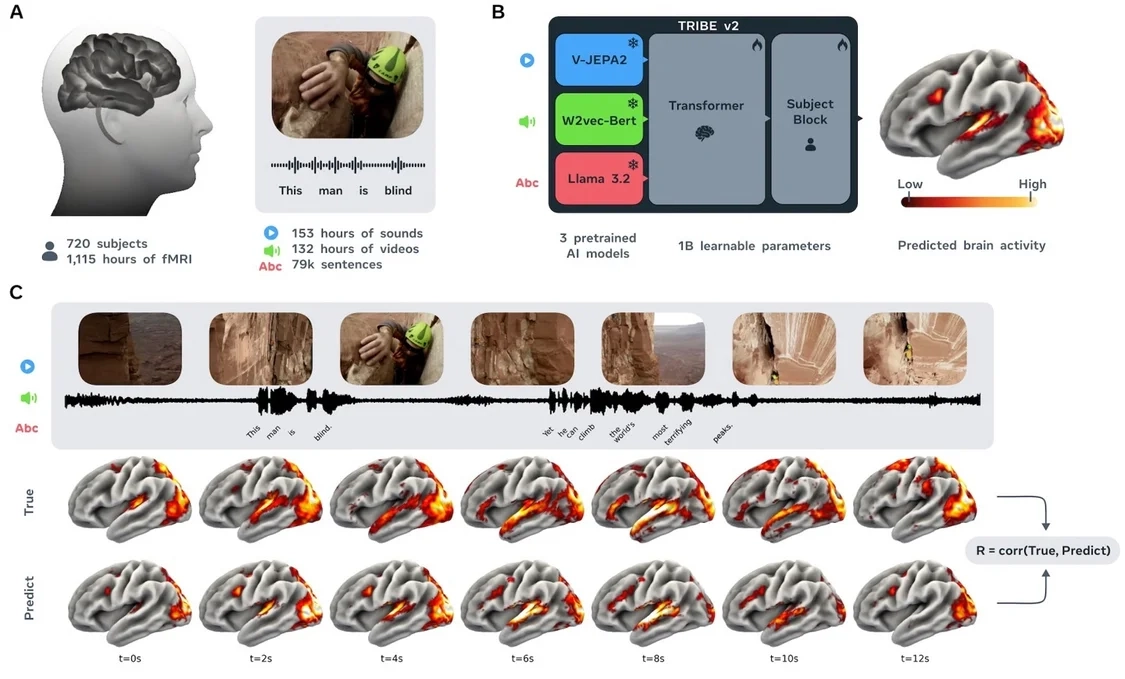
TRIBE v2 的核心逻辑是“多模态融合”。该模型在接收视频、音频与文本信息后,会分别借助 Video-JEPA-2、Wav2Vec-Bert-2.0 和 Llama 3.2 这三个预训练大模型来提取特征。之后,Transformer 架构会对这些信息进行整合,最终生成一张包含 7 万个“体素”(即 3D 像素)的高精度大脑活动图。
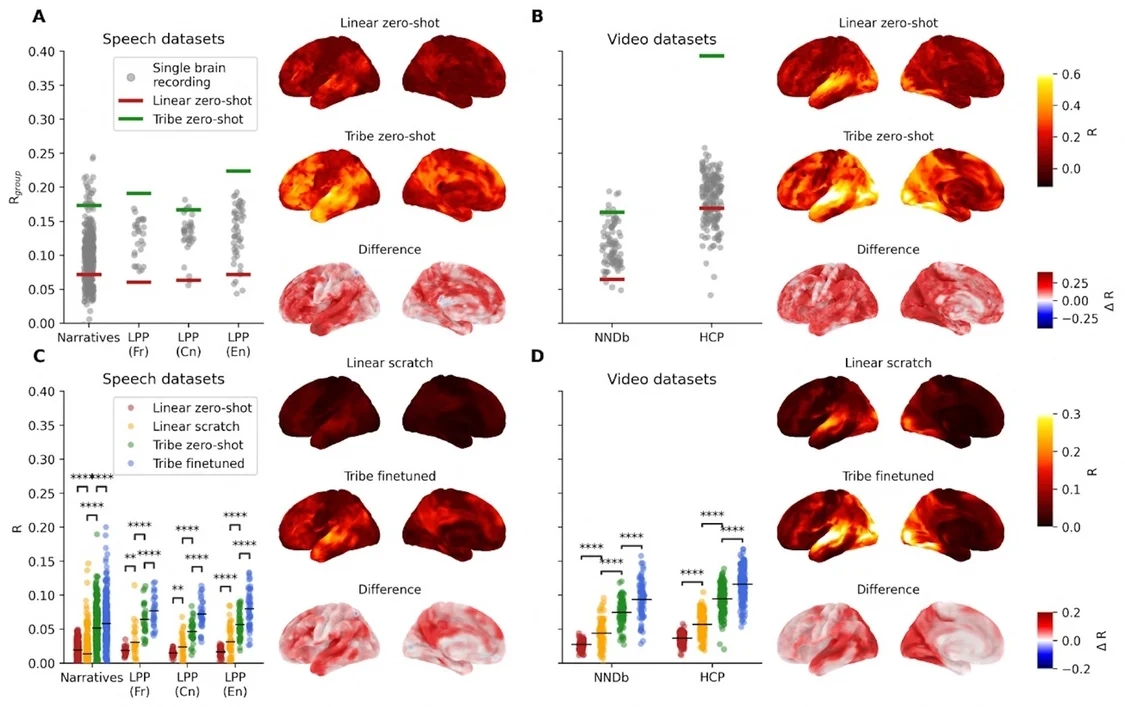
TRIBE v2 能够拓展应用到新的科目,不需要重新进行培训。绿色条代表模型的预测精准度;灰点则展示了单个脑部扫描和群体平均值之间的关联程度。而通过简短的微调(见底部),可以进一步提高其精度。| 图片来源:Meta
在性能方面,TRIBE v2的预测结果相较于单人真实脑扫描图更为清晰。真实的功能性磁共振成像(fMRI)往往会受到心跳、头部轻微移动等噪音的干扰,而TRIBE v2通过直接预测“调整后的平均反应”来去除这些杂音。实验结果显示,它的预测准确度远远超过传统线性模型,并且在计算机上成功复现了众多经典的神经科学实验。
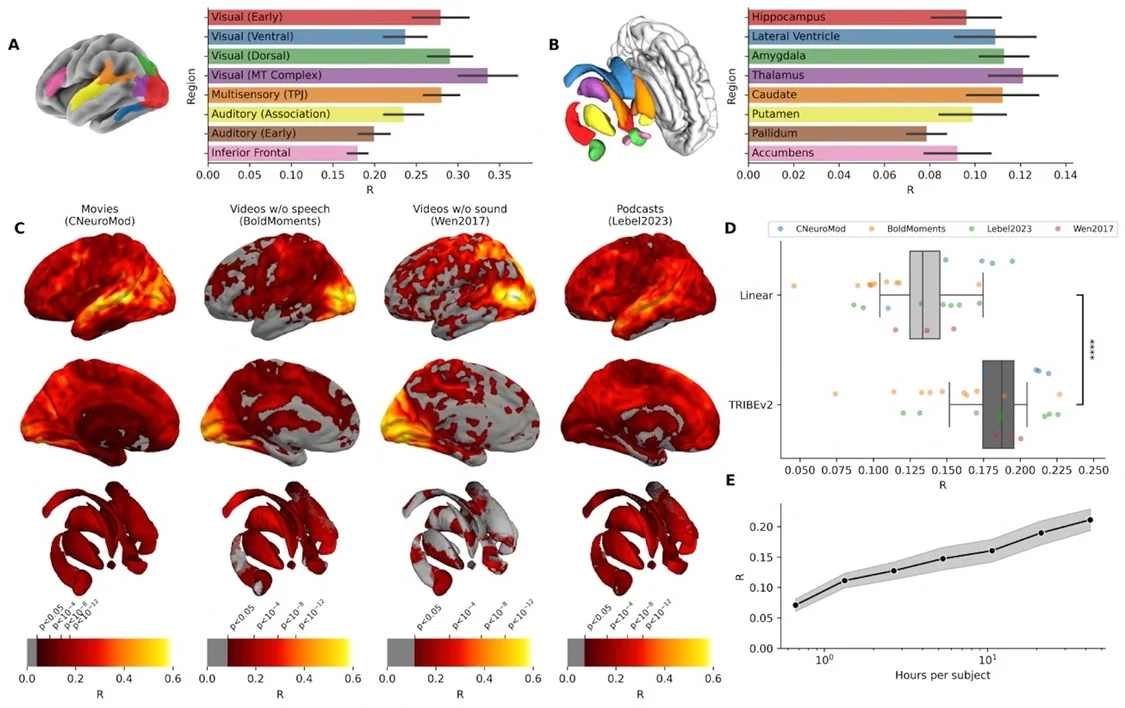
TRIBE v2 可对大脑皮层及皮层下区域的活动进行预测。不同刺激类型下的预测质量存在差异,且显著优于线性基线。随着训练数据的增多,预测准确性呈稳步上升趋势(右下角)。| 图片来源:Meta
该模型还展示了不同感官对特定大脑区域的激活方式:单独输入音频时,听觉皮层会被激活;而当输入多模态数据时,大脑颞叶、顶叶与枕叶交界处的预测准确率能大幅提升50%。
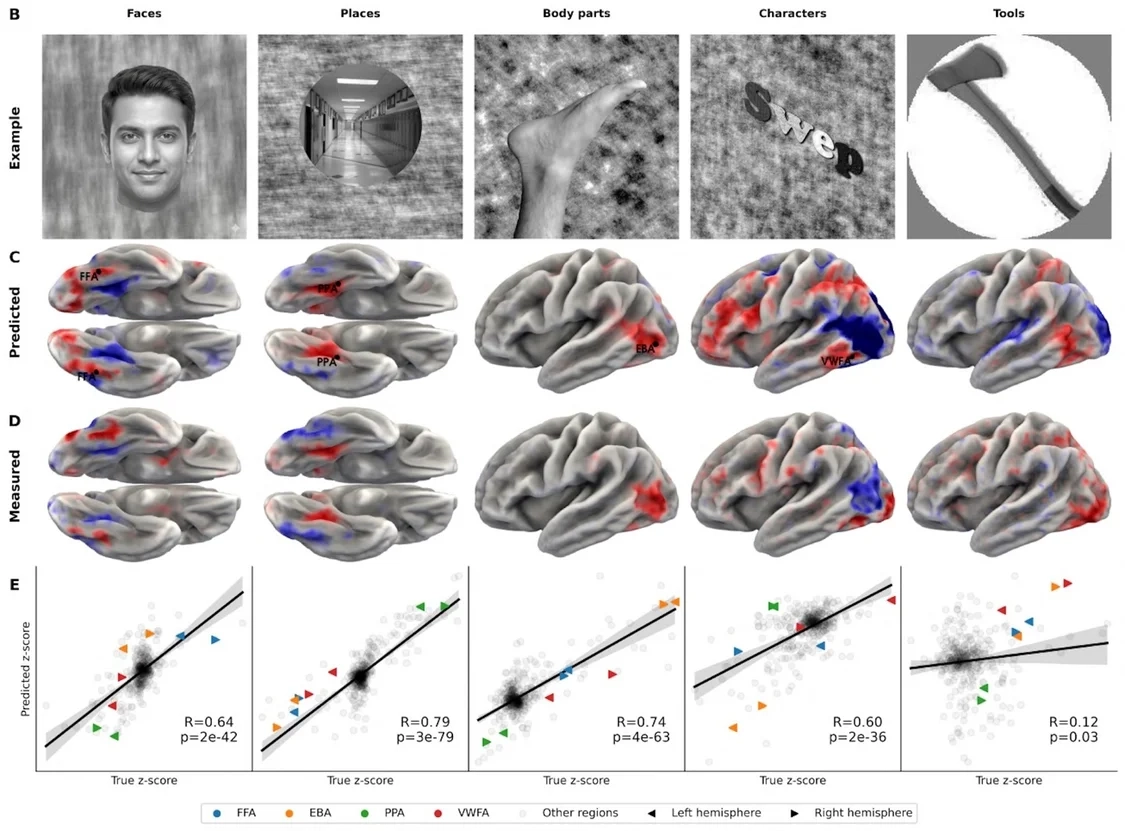
在视觉实验里,TRIBE v2 识别出了面部、地点、身体和角色这些已知的大脑专门区域。上方呈现的是实验所用图片,中间是模型的预测结果,下方则是实际测量得到的大脑活动情况。| 图片来源:Meta
尽管表现惊艳,TRIBE v2 仍存在局限性。它依赖存在数秒延迟的血流数据,无法捕捉毫秒级的神经动态,也缺乏触觉和嗅觉维度。
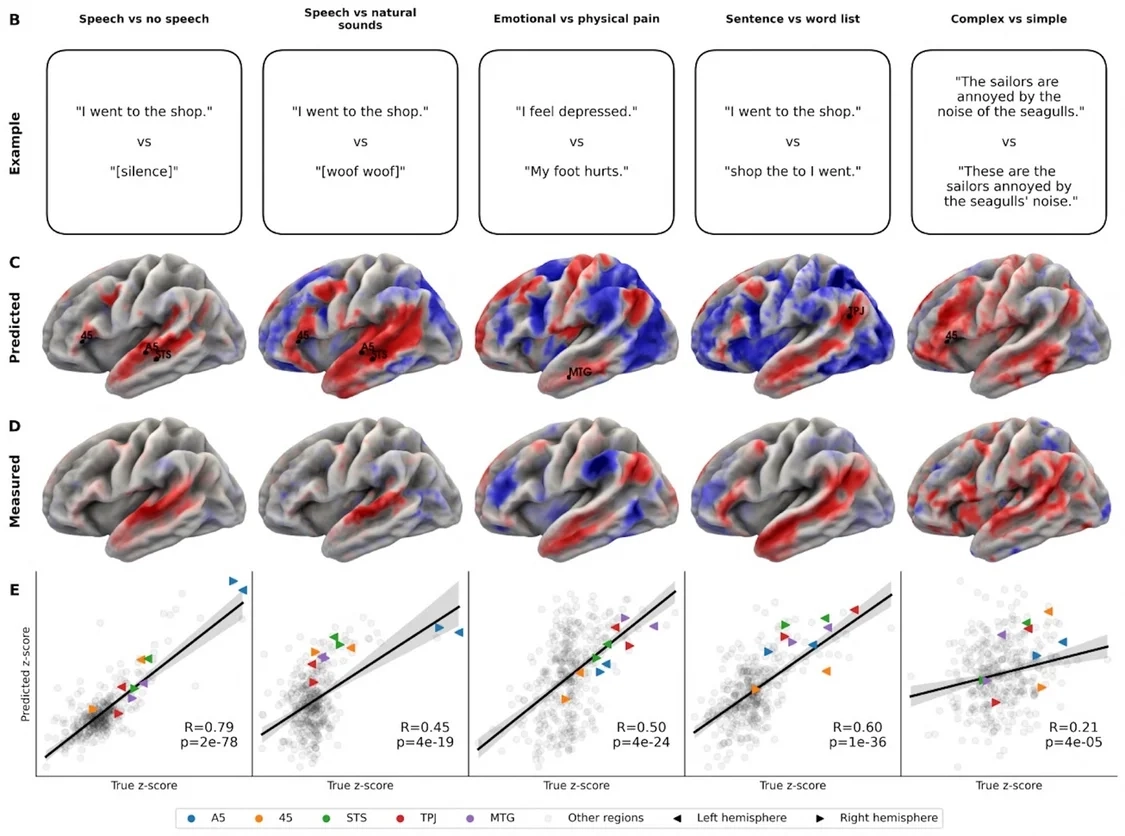
在语言实验里,TRIBE v2 重现了言语与沉默、情感与身体疼痛、句子与词汇列表的区分等经典神经语言学发现,其预测的激活模式和测量数据是一致的。| 图片来源:Meta
Meta 目前已全面开源该模型的代码与权重,未来将重点探索其在规划脑科学实验、构建类脑 AI 架构及诊断脑部疾病等领域的应用潜力。
 GamePass新层级被曝光仅可游玩Xbox第一方游戏
GamePass新层级被曝光仅可游玩Xbox第一方游戏
 接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
接连告破!《鬼灭之刃2》与《足球经理26》的D加密防线均被突破
 蓝色星原旅谣叶冠驼技能介绍
蓝色星原旅谣叶冠驼技能介绍
 愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
愤怒的小鸟星球大战2存档与内购修改指南_无限金币获取技巧
 小米手机的发展前景不容乐观,库存积压问题严重
小米手机的发展前景不容乐观,库存积压问题严重
 无双全明星中低调行动的男性角色奖杯解锁条件汇总
无双全明星中低调行动的男性角色奖杯解锁条件汇总
 最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
最新研究揭示游戏通关后出现抑郁情绪的奥秘,其中RPG游戏的表现尤为突出
 独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台
独立游戏作品《树林之夜》于2017年正式登陆PS4与PC两大平台